RAID
Isi · 1 Pendahuluan o 1.1 Perbedaan antara Disk fisik dan disk logis o 1.2 Membaca dan menulis data o 1.3 Apa itu RAID? o 1.4 Mengapa menggunakan RAID? o 1.5 Sejarah · 2 Konsep dasar yang digunakan oleh sistem RAID o 2.1 Caching o 2.2 Pencermina…
Isi
· 1 Pendahuluan
o 1.1 Perbedaan antara Disk fisik dan disk logis
o 1.2 Membaca dan menulis data
o 1.3 Apa itu RAID?
o 1.4 Mengapa menggunakan RAID?
o 1.5 Sejarah
· 2 Konsep dasar yang digunakan oleh sistem RAID
o 2.1 Caching
o 2.2 Pencerminan: Lebih dari satu salinan data
o 2.3 Striping: Sebagian data berada pada disk lain
o 2.4 Koreksi kesalahan dan kesalahan
o 2.5 Hot spares: menggunakan lebih banyak disk daripada yang dibutuhkan
o 2.6 Ukuran stripe dan ukuran chunk: menyebarkan data ke beberapa disk
o 2.7 Menyatukan disk: JBOD, penggabungan atau spanning
o 2.8 Klon Drive
o 2.9 Pengaturan yang berbeda
· 3 Dasar-dasar: tingkat RAID sederhana
o 3.1 Level RAID yang umum digunakan
§ 3.1.1 RAID 0 "striping"
§ 3.1.2 RAID 1 "pencerminan"
§ 3.1.3 RAID 5 "striping dengan paritas terdistribusi"
§ 3.1.4 Gambar
o 3.2 Level RAID yang digunakan lebih sedikit
§ 3.2.1 RAID 2
§ 3.2.2 RAID 3 "striping dengan paritas khusus"
§ 3.2.3 RAID 4 "striping dengan paritas khusus"
§ 3.2.4 RAID 6
§ 3.2.5 Gambar
o 3.3 Tingkat RAID non-standar
§ 3.3.1 Paritas ganda / Paritas diagonal
§ 3.3.2 RAID-DP
§ 3.3.3 RAID 1.5
§ 3.3.4 RAID 5E, RAID 5EE dan RAID 6E
§ 3.3.5 RAID 7
§ 3.3.6 Intel Matrix RAID
§ 3.3.7 Driver Linux MD RAID
§ 3.3.8 RAID Z
§ 3.3.9 Gambar
· 4 Menggabungkan level RAID
· 5 Membuat RAID
o 5.1 RAID Perangkat Lunak
o 5.2 RAID Perangkat Keras
o 5.3 RAID yang dibantu perangkat keras
· 6 Istilah berbeda yang terkait dengan kegagalan perangkat keras
o 6.1 Tingkat kegagalan
o 6.2 Waktu rata-rata untuk kehilangan data
o 6.3 Waktu rata-rata untuk pemulihan
o 6.4 Tingkat kesalahan bit yang tidak dapat dipulihkan
· 7 Masalah dengan RAID
o 7.1 Menambahkan disk di lain waktu
o 7.2 Kegagalan yang terkait
o 7.3 Atomisitas
o 7.4 Data yang tidak dapat dipulihkan
o 7.5 Keandalan cache tulis
o 7.6 Kompatibilitas peralatan
· 8 Apa yang bisa dan tidak bisa dilakukan RAID
o 8.1 Apa yang bisa dilakukan RAID
o 8.2 Apa yang tidak bisa dilakukan RAID
· 9 Contoh
· 10 Referensi
· 11 Situs web lain
RAID adalah akronim yang merupakan singkatan dari Redundant Array of Inexpensive Disks atau Redundant Array of Independent Disks. RAID adalah istilah yang digunakan dalam komputasi. Dengan RAID, beberapa hard disk dibuat menjadi satu disk logis. Ada beberapa cara berbeda yang dapat dilakukan. Masing-masing metode yang menyatukan hard disk memiliki beberapa manfaat dan kekurangan dibandingkan menggunakan drive sebagai disk tunggal, independen satu sama lain. Alasan utama mengapa RAID digunakan adalah:
- Untuk membuat kehilangan data lebih jarang terjadi. Ini dilakukan dengan memiliki beberapa salinan data.
- Untuk mendapatkan lebih banyak ruang penyimpanan dengan memiliki banyak disk yang lebih kecil.
- Untuk mendapatkan fleksibilitas yang lebih besar (Disk bisa diubah atau ditambahkan sementara sistem tetap berjalan)
- Untuk mendapatkan data lebih cepat.
Tidaklah mungkin untuk mencapai semua tujuan ini pada saat yang sama, sehingga pilihan perlu dibuat.
Ada juga beberapa hal buruk:
- Pilihan-pilihan tertentu dapat melindungi data yang hilang karena satu (atau sejumlah) disk gagal. Namun, pilihan-pilihan ini tidak melindungi terhadap data yang dihapus atau ditimpa.
- Dalam beberapa konfigurasi, RAID dapat mentolerir satu atau sejumlah disk yang gagal. Setelah disk yang gagal diganti, data perlu direkonstruksi. Tergantung pada konfigurasi dan ukuran disk, rekonstruksi ini bisa memakan waktu lama.
- Jenis kesalahan tertentu akan membuatnya tidak mungkin untuk membaca data
Sebagian besar karya tentang RAID didasarkan pada makalah yang ditulis pada tahun 1988.
Perusahaan-perusahaan telah menggunakan sistem RAID untuk menyimpan data mereka sejak teknologi ini dibuat. Ada berbagai cara di mana sistem RAID dapat dibuat. Sejak penemuannya, biaya untuk membangun sistem RAID telah turun banyak. Untuk alasan ini, bahkan beberapa komputer dan peralatan yang digunakan di rumah memiliki beberapa fungsi RAID. Sistem seperti itu dapat digunakan untuk menyimpan musik atau film, misalnya.
Pendahuluan
Perbedaan antara Disk fisik dan disk logis
Hard disk adalah bagian dari komputer. Hard disk normal menggunakan magnet untuk menyimpan informasi. Ketika hard disk digunakan, hard disk tersedia untuk sistem operasi. Di Microsoft Windows, setiap hard disk akan mendapatkan huruf drive (dimulai dengan C:, A: atau B: dicadangkan untuk floppy drive). Sistem operasi Unix dan Linux memiliki pohon direktori berakar tunggal. Ini berarti bahwa orang yang menggunakan komputer terkadang tidak tahu di mana informasi disimpan.(Agar adil, banyak pengguna Windows juga tidak tahu di mana data mereka disimpan).
Dalam komputasi, hard disk (yang merupakan perangkat keras, dan dapat disentuh) kadang-kadang disebut drive fisik atau disk fisik. Apa yang ditunjukkan oleh sistem operasi kepada pengguna kadang-kadang disebut logical disk. Drive fisik dapat dibagi menjadi beberapa bagian yang berbeda, yang disebut partisi disk. Biasanya, setiap partisi disk berisi satu sistem file. Sistem operasi akan menunjukkan setiap partisi seperti logical disk.
Oleh karena itu, bagi pengguna, baik setup dengan banyak disk fisik maupun setup dengan banyak disk logical akan terlihat sama. Pengguna tidak dapat memutuskan apakah "logical disk" sama dengan disk fisik, atau hanya merupakan bagian dari disk. Storage Area Networks (SAN) benar-benar mengubah pandangan ini. Semua yang terlihat dari SAN adalah sejumlah logical disk.
Membaca dan menulis data
Dalam komputer, data diatur dalam bentuk bit dan byte. Dalam kebanyakan sistem, 8 bit membentuk byte. Memori komputer menggunakan listrik untuk menyimpan data, hard disk menggunakan magnetisme. Oleh karena itu, ketika data ditulis pada disk, sinyal listrik diubah menjadi sinyal magnetis. Ketika data dibaca dari disk, konversi dilakukan ke arah lain: Sinyal listrik dibuat dari polaritas medan magnet.
Apa itu RAID?
RAID array menggabungkan dua atau lebih hard disk sehingga mereka membuat disk logis. Ada berbagai alasan mengapa hal ini dilakukan. Yang paling umum adalah:
- Menghentikan kehilangan data, ketika satu atau lebih disk array gagal.
- Mendapatkan transfer data yang lebih cepat.
- Mendapatkan kemampuan untuk mengganti disk sementara sistem tetap berjalan.
- Menggabungkan beberapa disk untuk mendapatkan kapasitas penyimpanan yang lebih besar; kadang-kadang banyak disk murah yang digunakan, daripada disk yang lebih mahal.
RAID dilakukan dengan menggunakan perangkat keras atau perangkat lunak khusus pada komputer. Hard disk yang digabungkan kemudian akan terlihat seperti satu hard disk bagi pengguna. Sebagian besar level RAID meningkatkan redundansi. Ini berarti bahwa mereka menyimpan data lebih sering, atau mereka menyimpan informasi tentang cara merekonstruksi data. Hal ini memungkinkan sejumlah disk gagal tanpa kehilangan data. Ketika disk yang gagal diganti, data yang seharusnya ada di dalamnya akan disalin atau dibangun kembali dari disk lain dari sistem. Hal ini bisa memakan waktu yang lama. Waktu yang dibutuhkan tergantung pada berbagai faktor, seperti ukuran array.
Mengapa menggunakan RAID?
Salah satu alasan mengapa banyak perusahaan menggunakan RAID adalah karena data dalam array dapat dengan mudah digunakan. Mereka yang menggunakan data tidak perlu menyadari bahwa mereka menggunakan RAID sama sekali. Ketika terjadi kegagalan dan array sedang dalam proses pemulihan, akses ke data akan lebih lambat. Mengakses data selama waktu ini juga akan memperlambat proses pemulihan, tetapi ini masih jauh lebih cepat daripada tidak dapat bekerja dengan data sama sekali. Tergantung pada level RAID, disk mungkin tidak gagal saat disk baru sedang dipersiapkan untuk digunakan. Disk yang gagal pada saat itu akan mengakibatkan kehilangan semua data dalam array.
Cara yang berbeda untuk menggabungkan disk disebut level RAID. Angka yang lebih besar untuk level belum tentu lebih baik. Level RAID yang berbeda memiliki tujuan yang berbeda. Beberapa level RAID memerlukan disk khusus dan pengontrol khusus.
Sejarah
Pada tahun 1978, seorang pria bernama Norman Ken Ouchi, yang bekerja di IBM, membuat saran yang menggambarkan rencana untuk apa yang kemudian menjadi RAID 5. Rencana tersebut juga menggambarkan sesuatu yang mirip dengan RAID 1, serta perlindungan bagian dari RAID 4.
Para pekerja di Universitas Berkeley membantu merencanakan penelitian pada tahun 1987. Mereka mencoba memungkinkan teknologi RAID untuk mengenali dua hard drive, bukan hanya satu. Mereka menemukan bahwa ketika teknologi RAID memiliki dua hard drive, teknologi ini memiliki penyimpanan yang jauh lebih baik daripada hanya dengan satu hard drive. Namun, lebih sering mengalami crash.
Pada tahun 1988, berbagai jenis RAID (1 sampai 5), ditulis oleh David Patterson, Garth Gibson dan Randy Katz dalam artikel mereka, yang berjudul "A Case for Redundant Arrays of Inexpensive Disks (RAID)". Artikel ini adalah yang pertama kali menyebut teknologi baru RAID dan nama tersebut menjadi resmi.


Konsep dasar yang digunakan oleh sistem RAID
RAID menggunakan beberapa ide dasar, yang dijelaskan dalam artikel "RAID: High-Performance, Reliable Secondary Storage" oleh Peter Chen dan yang lainnya, yang diterbitkan pada tahun 1994.
Caching
Caching adalah teknologi yang juga memiliki kegunaan dalam sistem RAID. Ada berbagai jenis cache yang digunakan dalam sistem RAID:
- Sistem operasi
- Pengontrol RAID
- Susunan disk perusahaan
Dalam sistem modern, permintaan tulis ditampilkan sebagai selesai ketika data telah ditulis ke cache. Ini tidak berarti bahwa data telah ditulis ke disk. Permintaan dari cache tidak selalu ditangani dalam urutan yang sama dengan urutan penulisan ke cache. Hal ini memungkinkan, jika sistem gagal, kadang-kadang beberapa data belum ditulis ke disk yang terlibat. Untuk alasan ini, banyak sistem memiliki cache yang didukung oleh baterai.
Pencerminan: Lebih dari satu salinan data
Ketika berbicara tentang cermin, ini adalah ide yang sangat sederhana. Alih-alih data hanya berada di satu tempat, ada beberapa salinan data. Salinan-salinan ini biasanya berada pada hard disk (atau partisi disk) yang berbeda. Jika ada dua salinan, salah satunya bisa gagal tanpa data terpengaruh (karena masih ada pada salinan lainnya). Mirroring juga dapat memberikan dorongan saat membaca data. Data akan selalu diambil dari disk tercepat yang merespons. Namun, menulis data lebih lambat, karena semua disk perlu diperbarui.
Striping: Sebagian data berada pada disk lain
Dengan striping, data dibagi menjadi beberapa bagian yang berbeda. Bagian-bagian ini kemudian berakhir pada disk yang berbeda (atau partisi disk). Ini berarti, bahwa penulisan data lebih cepat, karena bisa dilakukan secara paralel. Ini tidak berarti bahwa tidak akan ada kesalahan, karena setiap blok data hanya ditemukan pada satu disk.
Koreksi kesalahan dan kesalahan
Adalah mungkin untuk menghitung berbagai jenis checksum. Beberapa metode penghitungan checksum memungkinkan menemukan kesalahan. Sebagian besar level RAID yang menggunakan redundansi dapat melakukan ini. Beberapa metode lebih sulit dilakukan, tetapi mereka memungkinkan untuk tidak hanya mendeteksi kesalahan, tetapi juga memperbaikinya.
Hot spares: menggunakan lebih banyak disk daripada yang dibutuhkan
Banyak cara untuk memiliki RAID mendukung sesuatu yang disebut hot spare. Hot spare adalah disk kosong yang tidak digunakan dalam operasi normal. Ketika sebuah disk gagal, data dapat langsung disalin ke hot spare disk. Dengan begitu, disk yang gagal perlu diganti dengan drive kosong baru untuk menjadi hot spare.
Ukuran stripe dan ukuran chunk: menyebarkan data ke beberapa disk
RAID bekerja dengan menyebarkan data ke beberapa disk. Dua istilah yang sering digunakan dalam konteks ini adalah stripe size dan chunk size.
Ukuran chunk adalah blok data terkecil yang ditulis ke satu disk array. Ukuran stripe adalah ukuran blok data yang akan disebarkan ke semua disk. Dengan begitu, dengan empat disk, dan ukuran stripe 64 kilobyte (kB), 16 kB akan ditulis ke setiap disk. Oleh karena itu, ukuran chunk dalam contoh ini adalah 16 kB. Membuat ukuran stripe lebih besar akan berarti laju transfer data yang lebih cepat, tetapi juga latensi maksimum yang lebih besar. Dalam hal ini, ini adalah waktu yang diperlukan untuk mendapatkan blok data.
Menyatukan disk: JBOD, penggabungan atau spanning
Banyak pengendali (dan juga perangkat lunak) dapat menyatukan disk dengan cara berikut: Ambil disk pertama, sampai habis, lalu ambil disk kedua, dan seterusnya. Dengan cara itu, beberapa disk yang lebih kecil terlihat seperti disk yang lebih besar. Ini bukan RAID yang sebenarnya, karena tidak ada redundansi. Juga, spanning dapat menggabungkan disk di mana RAID 0 tidak dapat melakukan apapun. Umumnya, ini disebut hanya sekelompok disk (JBOD).
Ini seperti kerabat jauh RAID karena drive logis terbuat dari drive fisik yang berbeda. Penggabungan kadang-kadang digunakan untuk mengubah beberapa drive kecil menjadi satu drive berguna yang lebih besar. Hal ini tidak dapat dilakukan dengan RAID 0. Misalnya, JBOD dapat menggabungkan drive 3 GB, 15 GB, 5,5 GB, dan 12 GB ke dalam drive logis sebesar 35,5 GB, yang sering kali lebih berguna daripada drive saja.
Dalam diagram di sebelah kanan, data digabungkan dari akhir disk 0 (blok A63) ke awal disk 1 (blok A64); akhir disk 1 (blok A91) ke awal disk 2 (blok A92). Jika RAID 0 digunakan, maka disk 0 dan disk 2 akan dipotong menjadi 28 blok, ukuran disk terkecil dalam array (disk 1) untuk ukuran total 84 blok.
Beberapa pengendali RAID menggunakan JBOD untuk berbicara tentang bekerja pada drive tanpa fitur RAID. Setiap drive muncul secara terpisah dalam sistem operasi. JBOD ini tidak sama dengan penggabungan.
Banyak sistem Linux menggunakan istilah "linear mode" atau "append mode". Implementasi Mac OS X 10.4 - yang disebut "Concatenated Disk Set" - tidak meninggalkan pengguna dengan data yang dapat digunakan pada drive yang tersisa jika salah satu drive gagal dalam set disk yang digabungkan, meskipun disk sebaliknya beroperasi seperti yang dijelaskan di atas.
Penggabungan adalah salah satu kegunaan Logical Volume Manager di Linux. Ini dapat digunakan untuk membuat drive virtual.
Klon Drive
Kebanyakan hard disk modern memiliki standar yang disebut Self-Monitoring, Analysis and Reporting Technology (S.M.A.R.T). SMART memungkinkan untuk memonitor hal-hal tertentu pada hard disk drive. Kontroler tertentu memungkinkan untuk mengganti satu hard disk bahkan sebelum gagal, misalnya karena S.M.A.R.T atau tes disk lain melaporkan terlalu banyak kesalahan yang dapat diperbaiki. Untuk melakukan ini, controller akan menyalin semua data ke drive cadangan panas. Setelah ini, disk dapat diganti dengan disk lain (yang hanya akan menjadi hot spare baru).
Pengaturan yang berbeda
Pengaturan disk dan bagaimana mereka menggunakan teknik-teknik di atas mempengaruhi performa dan keandalan sistem. Bila lebih banyak disk yang digunakan, salah satu disk lebih mungkin gagal. Karena itu, mekanisme harus dibangun untuk dapat menemukan dan memperbaiki kesalahan. Hal ini membuat keseluruhan sistem lebih andal, karena mampu bertahan dan memperbaiki kegagalan.

Dasar-dasar: tingkat RAID sederhana
Tingkat RAID yang umum digunakan
RAID 0 "striping"
RAID 0 tidak benar-benar RAID karena tidak redundan. Dengan RAID 0, disk hanya disatukan untuk membuat disk yang besar. Ini disebut "striping". Ketika satu disk gagal, seluruh array gagal. Oleh karena itu, RAID 0 jarang digunakan untuk data penting, tetapi membaca dan menulis data dari disk bisa lebih cepat dengan striping karena setiap disk membaca bagian dari file pada saat yang sama.
Dengan RAID 0, blok disk yang datang setelah satu sama lain biasanya ditempatkan pada disk yang berbeda. Untuk alasan ini, semua disk yang digunakan oleh RAID 0 harus berukuran sama.
RAID 0 sering digunakan untuk Swapspace pada Linux atau sistem operasi Unix-like.
RAID 1 "pencerminan"
Dengan RAID 1, dua disk disatukan. Keduanya memegang data yang sama, yang satu "mirroring" yang lain. Ini adalah konfigurasi yang mudah dan cepat baik diimplementasikan dengan pengontrol perangkat keras atau dengan perangkat lunak.
RAID 5 "striping dengan paritas terdistribusi"
RAID Level 5 adalah apa yang mungkin digunakan sebagian besar waktu. Setidaknya tiga hard disk diperlukan untuk membangun array penyimpanan RAID 5. Setiap blok data akan disimpan di tiga tempat yang berbeda. Dua dari tempat ini akan menyimpan blok apa adanya, yang ketiga akan menyimpan checksum. Checksum ini adalah kasus khusus dari kode Reed-Solomon yang hanya menggunakan penambahan bitwise. Biasanya, ini dihitung dengan menggunakan metode XOR. Karena metode ini simetris, satu blok data yang hilang dapat dibangun kembali dari blok data lainnya dan checksum. Untuk setiap blok, disk yang berbeda akan memegang blok paritas yang memegang checksum. Ini dilakukan untuk meningkatkan redundansi. Disk apa pun bisa gagal. Secara keseluruhan, akan ada satu disk yang memegang checksum, sehingga total kapasitas yang dapat digunakan adalah kapasitas semua disk kecuali satu. Ukuran disk logis yang dihasilkan adalah ukuran semua disk bersama-sama, kecuali satu disk yang menyimpan informasi paritas.
Tentu saja ini lebih lambat daripada RAID level 1, karena pada setiap penulisan, semua disk perlu dibaca untuk menghitung dan memperbarui informasi paritas. Kinerja baca RAID 5 hampir sama baiknya dengan RAID 0 untuk jumlah disk yang sama. Kecuali untuk blok paritas, distribusi data di atas drive mengikuti pola yang sama dengan RAID 0. Alasan RAID 5 sedikit lebih lambat adalah karena disk harus melewati blok paritas.
RAID 5 dengan disk yang gagal akan terus bekerja. Ini dalam mode terdegradasi. RAID 5 yang terdegradasi bisa sangat lambat. Untuk alasan ini disk tambahan sering ditambahkan. Ini disebut disk cadangan panas. Jika sebuah disk gagal, data dapat langsung dibangun kembali ke disk tambahan. RAID 5 juga dapat dilakukan dalam perangkat lunak dengan cukup mudah.
Terutama karena masalah performa dari array RAID 5 yang gagal, beberapa pakar database telah membentuk kelompok yang disebut BAARF - Battle Against Any Raid Five.
Jika sistem gagal ketika ada penulisan aktif, paritas dari sebuah stripe mungkin menjadi tidak konsisten dengan data. Jika ini tidak diperbaiki sebelum disk atau blok gagal, kehilangan data dapat terjadi. Paritas yang salah akan digunakan untuk merekonstruksi blok yang hilang dalam stripe itu. Masalah ini kadang-kadang dikenal sebagai "lubang tulis". Battery-backed caches dan teknik serupa biasanya digunakan untuk mengurangi kemungkinan terjadinya hal ini.
Gambar
· 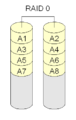
RAID 0 hanya menempatkan blok-blok yang berbeda pada disk yang berbeda. Tidak ada redundansi.
· 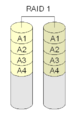
Dengan Raid 1, setiap blok ada di kedua disk
· 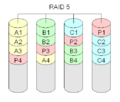
RAID 5 menghitung checksum khusus untuk data. Baik blok dengan checksum maupun blok dengan data didistribusikan ke semua disk.
Tingkat RAID yang digunakan lebih sedikit
RAID 2
Ini digunakan dengan komputer yang sangat besar. Disk mahal khusus dan pengontrol khusus diperlukan untuk menggunakan RAID Level 2. Data didistribusikan pada tingkat bit (semua tingkat lainnya menggunakan tindakan tingkat byte). Perhitungan khusus dilakukan. Data dibagi menjadi urutan bit yang statis. 8 bit data dan 2 bit paritas disatukan. Kemudian kode Hamming dihitung. Fragmen-fragmen kode Hamming kemudian didistribusikan ke disk yang berbeda.
RAID 2 adalah satu-satunya level RAID yang dapat memperbaiki kesalahan, level RAID lainnya hanya dapat mendeteksinya. Ketika mereka menemukan bahwa informasi yang dibutuhkan tidak masuk akal, mereka hanya akan membangunnya kembali. Hal ini dilakukan dengan perhitungan, menggunakan informasi pada disk lain. Jika informasi itu hilang atau salah, mereka tidak bisa berbuat banyak. Karena menggunakan kode Hamming, RAID 2 dapat mengetahui bagian mana dari informasi yang salah, dan hanya mengoreksi bagian itu.
RAID 2 membutuhkan setidaknya 10 disk untuk bekerja. Karena kerumitannya dan kebutuhannya akan perangkat keras yang sangat mahal dan khusus, RAID 2 tidak lagi banyak digunakan.
RAID 3 "striping dengan paritas khusus"
Raid Level 3 sama seperti RAID Level 0. Disk tambahan ditambahkan untuk menyimpan informasi paritas. Hal ini dilakukan dengan penambahan bitwise dari nilai blok pada disk lainnya. Informasi paritas disimpan pada disk terpisah (khusus). Hal ini tidak baik, karena jika disk paritas rusak, informasi paritas akan hilang.
RAID Level 3 biasanya dilakukan dengan setidaknya 3 disk. Pengaturan dua disk identik dengan RAID Level 0.
RAID 4 "striping dengan paritas khusus"
Ini sangat mirip dengan RAID 3, kecuali bahwa informasi paritas dihitung pada blok yang lebih besar, dan bukan byte tunggal. Ini seperti RAID 5. Setidaknya tiga disk diperlukan untuk array RAID 4.
RAID 6
RAID level 6 bukanlah level RAID yang asli. Ini menambahkan blok paritas tambahan ke array RAID 5. Diperlukan setidaknya empat disk (dua disk untuk kapasitas, dua disk untuk redundansi). RAID 5 dapat dilihat sebagai kasus khusus dari kode Reed-Solomon. RAID 5 adalah kasus khusus, meskipun demikian, RAID 5 hanya membutuhkan penambahan dalam bidang Galois GF(2). Ini mudah dilakukan dengan XOR. RAID 6 memperluas perhitungan ini. Ini bukan lagi kasus khusus, dan semua perhitungan perlu dilakukan. Dengan RAID 6, checksum tambahan (disebut polinomial) digunakan, biasanya dari GF (28 ). Dengan pendekatan ini, dimungkinkan untuk melindungi terhadap sejumlah disk yang gagal. RAID 6 adalah untuk kasus menggunakan dua checksum untuk melindungi terhadap hilangnya dua disk.
Seperti RAID 5, paritas dan data berada pada disk yang berbeda untuk setiap blok. Dua blok paritas juga terletak pada disk yang berbeda.
Ada berbagai cara untuk melakukan RAID 6. Mereka berbeda dalam kinerja tulisannya, dan dalam berapa banyak perhitungan yang dibutuhkan. Mampu melakukan penulisan yang lebih cepat biasanya berarti lebih banyak perhitungan yang dibutuhkan.
RAID 6 lebih lambat dari RAID 5, tetapi memungkinkan RAID untuk melanjutkan dengan dua disk yang gagal. RAID 6 menjadi populer karena memungkinkan array untuk dibangun kembali setelah kegagalan drive tunggal bahkan jika salah satu disk yang tersisa memiliki satu atau lebih bad sector.
Gambar
· 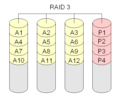
RAID 3 sama seperti RAID level 0. Disk tambahan ditambahkan yang akan menyimpan checksum untuk setiap blok data.
· 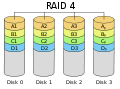
RAID 4 mirip dengan RAID level 3, tetapi menghitung paritas pada blok data yang lebih besar
· 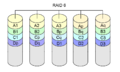
RAID 6 mirip dengan RAID 5, tetapi menghitung dua checksum yang berbeda. Hal ini memungkinkan dua disk gagal, tanpa kehilangan data.
Tingkat RAID yang tidak standar
Paritas ganda / Paritas diagonal
RAID 6 menggunakan dua blok paritas. Ini dihitung dengan cara khusus melalui polinomial. RAID paritas ganda (juga disebut RAID paritas diagonal) menggunakan polinomial yang berbeda untuk masing-masing blok paritas ini. Baru-baru ini, asosiasi industri yang mendefinisikan RAID mengatakan bahwa RAID paritas ganda adalah bentuk RAID 6 yang berbeda.
RAID-DP
RAID-DP adalah cara lain untuk memiliki paritas ganda.
RAID 1.5
RAID 1.5 (jangan disamakan dengan RAID 15, yang berbeda) adalah implementasi RAID berpemilik. Seperti RAID 1, RAID 1.5 hanya menggunakan dua disk, tetapi melakukan striping dan mirroring (mirip dengan RAID 10). Sebagian besar hal dilakukan dalam perangkat keras.
RAID 5E, RAID 5EE dan RAID 6E
RAID 5E, RAID 5EE, dan RAID 6E (dengan tambahan E untuk Enhanced) umumnya mengacu pada berbagai jenis RAID 5 atau RAID 6 dengan cadangan panas. Dengan implementasi ini, drive cadangan panas bukanlah drive fisik. Sebaliknya, itu ada dalam bentuk ruang kosong pada disk. Hal ini meningkatkan performa, tetapi ini berarti bahwa hot spare tidak dapat dibagi di antara array yang berbeda. Skema ini diperkenalkan oleh IBM ServeRAID sekitar tahun 2001.
RAID 7
Ini adalah implementasi eksklusif. Ini menambahkan caching ke array RAID 3 atau RAID 4.
Intel Matrix RAID
Beberapa papan utama Intel memiliki chip RAID yang memiliki fitur ini. Fitur ini menggunakan dua atau tiga disk, dan kemudian mempartisi mereka secara merata untuk membentuk kombinasi tingkat RAID 0, RAID 1, RAID 5 atau RAID 1+0.
Driver Linux MD RAID
Ini adalah nama untuk driver yang memungkinkan untuk melakukan RAID software dengan Linux. Selain RAID normal level 0-6, juga memiliki implementasi RAID 10. Sejak Kernel 2.6.9, RAID 10 adalah level tunggal. Implementasi ini memiliki beberapa fitur non-standar.
RAID Z
Sun telah mengimplementasikan sistem berkas yang disebut ZFS. Sistem file ini dioptimalkan untuk menangani data dalam jumlah besar. Ini termasuk Logical Volume Manager. Ini juga termasuk fitur yang disebut RAID-Z. Sistem ini menghindari masalah yang disebut RAID 5 write hole karena memiliki kebijakan copy-on-write: RAID-Z tidak menimpa data secara langsung, tetapi menulis data baru di lokasi baru pada disk. Ketika penulisan berhasil, data lama dihapus. Ini menghindari kebutuhan untuk operasi baca-modifikasi-tulis untuk penulisan kecil, karena hanya menulis garis-garis penuh. Blok-blok kecil dicerminkan dan bukannya dilindungi paritas, yang dimungkinkan karena sistem file mengetahui cara penyimpanan diatur. Oleh karena itu, sistem ini dapat mengalokasikan ruang ekstra jika perlu. Ada juga RAID-Z2 yang menggunakan dua bentuk paritas untuk mencapai hasil yang mirip dengan RAID 6: kemampuan untuk bertahan hingga dua kegagalan drive tanpa kehilangan data.
Gambar
· 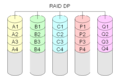
Diagram pengaturan RAID DP (Paritas Ganda).
· 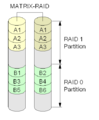
Pengaturan Matrix RAID.
Menggabungkan level RAID
Dengan RAID, disk yang berbeda dapat disatukan untuk mendapatkan disk logis, pengguna hanya akan melihat disk logis. Masing-masing level RAID yang disebutkan di atas memiliki poin baik dan buruk. Tetapi RAID juga dapat bekerja dengan logical disk. Dengan begitu salah satu level RAID di atas dapat digunakan dengan sekumpulan logical disk. Banyak orang yang mencatatnya dengan menuliskan angka-angka secara bersamaan. Terkadang, mereka menulis '+' atau '&' di antaranya. Kombinasi yang umum (menggunakan dua level) adalah sebagai berikut:
- RAID 0+1: Dua atau lebih array RAID 0 digabungkan ke array RAID 1; Ini disebut Mirror of stripes
- RAID 1+0: Sama seperti RAID 0+1, tetapi tingkat RAID dibalik; Stripe of Mirrors. Hal ini membuat kegagalan disk lebih jarang daripada RAID 0+1 di atas.
- RAID 5+0: Stripe beberapa RAID 5 dengan RAID 0. Satu disk dari setiap RAID 5 bisa gagal, tetapi menjadikan RAID 5 itu sebagai titik kegagalan tunggal; jika disk lain dari larik itu gagal, semua data larik akan hilang.
- RAID 5+1: Cermin satu set RAID 5: Dalam situasi di mana RAID terbuat dari enam disk, tiga disk mana pun bisa gagal (tanpa kehilangan data).
- RAID 6+0: Menggariskan beberapa susunan RAID 6 di atas RAID 0; Dua disk dari setiap RAID 6 bisa gagal tanpa kehilangan data.
Dengan enam disk masing-masing 300 GB, kapasitas total 1,8 TB, dimungkinkan untuk membuat RAID 5, dengan ruang yang dapat digunakan 1,5 TB. Dalam array itu, satu disk bisa gagal tanpa kehilangan data. Dengan RAID 50, ruang dikurangi menjadi 1,2 TB, tetapi satu disk dari setiap RAID 5 bisa gagal, ditambah lagi ada peningkatan kinerja yang nyata. RAID 51 mengurangi ukuran yang dapat digunakan hingga 900 GB, tetapi memungkinkan tiga drive gagal.
· 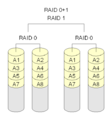
RAID 0+1: Beberapa array RAID 0 dikombinasikan dengan RAID 1
· 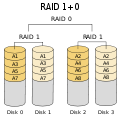
RAID 1+0: Lebih tangguh daripada RAID 0+1; mendukung kegagalan beberapa drive, selama tidak ada dua drive yang membuat cermin gagal.
· 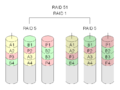
RAID 5+1: Tiga drive ini bisa gagal, tanpa kehilangan data.
Membuat RAID
Ada berbagai cara untuk membuat RAID. Ini bisa dilakukan dengan perangkat lunak, atau dengan perangkat keras.
RAID Perangkat Lunak
RAID dapat dibuat dengan perangkat lunak dalam dua cara yang berbeda. Dalam kasus RAID Perangkat Lunak, disk dihubungkan seperti hard disk normal. Komputerlah yang membuat RAID bekerja. Ini berarti bahwa untuk setiap akses, CPU juga perlu melakukan perhitungan untuk RAID. Perhitungan untuk RAID 0 atau RAID 1 sederhana. Namun, perhitungan untuk RAID 5, RAID 6, atau salah satu tingkat RAID gabungan bisa menjadi banyak pekerjaan. Dalam RAID perangkat lunak, booting otomatis dari array yang gagal mungkin merupakan hal yang sulit dilakukan. Akhirnya, cara RAID dilakukan dalam perangkat lunak tergantung pada sistem operasi yang digunakan; umumnya tidak mungkin untuk membangun kembali array RAID Perangkat Lunak dengan sistem operasi yang berbeda. Sistem operasi biasanya menggunakan partisi hard disk daripada seluruh hard disk untuk membuat array RAID.
RAID Perangkat Keras
RAID juga dapat dibuat dengan perangkat keras. Dalam hal ini, digunakan disk controller khusus; kartu controller ini menyembunyikan fakta bahwa ia melakukan RAID dari sistem operasi dan pengguna. Perhitungan informasi checksum, dan perhitungan lain yang berhubungan dengan RAID dilakukan pada microchip khusus dalam controller tersebut. Hal ini membuat RAID tidak tergantung pada sistem operasi. Sistem operasi tidak akan melihat RAID, ia akan melihat disk tunggal. Produsen yang berbeda melakukan RAID dengan cara yang berbeda. Ini berarti bahwa RAID yang dibangun dengan satu pengontrol RAID perangkat keras tidak dapat dibangun kembali oleh pengontrol RAID lain dari produsen yang berbeda. Pengontrol RAID perangkat keras seringkali mahal untuk dibeli.
RAID yang dibantu perangkat keras
Ini adalah campuran antara RAID perangkat keras dan RAID perangkat lunak. RAID yang dibantu perangkat keras menggunakan chip pengontrol khusus (seperti RAID perangkat keras), tetapi chip ini tidak dapat melakukan banyak operasi. Ini hanya aktif ketika sistem dimulai; segera setelah sistem operasi terisi penuh, konfigurasi ini seperti RAID software. Beberapa motherboard memiliki fungsi RAID untuk disk yang terpasang; paling sering, fungsi RAID ini dilakukan sebagai RAID yang dibantu perangkat keras. Ini berarti bahwa software khusus diperlukan untuk dapat menggunakan fungsi RAID ini dan untuk dapat memulihkan dari disk yang gagal.
Berbagai istilah yang terkait dengan kegagalan perangkat keras
Ada berbagai istilah yang digunakan apabila berbicara tentang kegagalan perangkat keras:
Tingkat kegagalan
Tingkat kegagalan adalah seberapa sering sistem gagal. Waktu rata-rata kegagalan (MTTF) atau waktu rata-rata antara kegagalan (MTBF) dari sistem RAID sama dengan komponennya. Sistem RAID tidak dapat melindungi dari kegagalan hard drive individualnya. Namun, jenis RAID yang lebih rumit (apa pun di luar "striping" atau "penggabungan") dapat membantu menjaga data tetap utuh meskipun hard drive individu gagal.
Waktu rata-rata untuk kehilangan data
Waktu rata-rata untuk kehilangan data (MTTDL) memberikan waktu rata-rata sebelum kehilangan data terjadi dalam array yang diberikan. Waktu rata-rata untuk kehilangan data dari RAID yang diberikan mungkin lebih tinggi atau lebih rendah daripada hard disk-nya. Ini tergantung pada jenis RAID yang digunakan.
Waktu rata-rata untuk pemulihan
Array yang memiliki redundansi dapat pulih dari beberapa kegagalan. Waktu rata-rata untuk pemulihan menunjukkan berapa lama waktu yang dibutuhkan sampai array yang gagal kembali ke keadaan normal. Ini menambahkan waktu untuk mengganti mekanisme disk yang gagal serta waktu untuk membangun kembali array (yaitu untuk mereplikasi data untuk redundansi).
Tingkat kesalahan bit yang tidak dapat dipulihkan
Tingkat kesalahan bit yang tidak dapat dipulihkan (UBE) memberi tahu berapa lama disk drive tidak akan dapat memulihkan data setelah menggunakan kode cyclic redundancy check (CRC) dan beberapa kali percobaan ulang.
Masalah dengan RAID
Ada juga masalah tertentu dengan gagasan atau teknologi di balik RAID:
Menambahkan disk di lain waktu
Level RAID tertentu memungkinkan untuk memperpanjang array hanya dengan menambahkan hard disk, di lain waktu. Informasi seperti blok paritas sering tersebar pada beberapa disk. Menambahkan disk ke array berarti bahwa reorganisasi menjadi perlu. Reorganisasi seperti itu seperti membangun kembali array, bisa memakan waktu lama. Ketika hal ini dilakukan, ruang tambahan mungkin belum tersedia, karena sistem file pada array, dan sistem operasi perlu diberitahu tentang hal itu. Beberapa sistem file tidak mendukung untuk ditumbuhkan setelah dibuat. Dalam kasus seperti itu, semua data perlu dicadangkan, array perlu dibuat ulang dengan tata letak yang baru, dan data perlu dipulihkan ke dalamnya.
Pilihan lain untuk menambah penyimpanan adalah dengan membuat array baru, dan membiarkan logical volume manager menangani situasi tersebut. Hal ini memungkinkan untuk mengembangkan hampir semua sistem RAID, bahkan RAID1 (yang dengan sendirinya terbatas pada dua disk).
Kegagalan yang terkait
Mekanisme koreksi kesalahan dalam RAID mengasumsikan bahwa kegagalan drive bersifat independen. Dimungkinkan untuk menghitung seberapa sering sebuah peralatan bisa gagal dan mengatur array untuk membuat kehilangan data sangat mustahil.
Namun demikian, dalam praktiknya, drive sering dibeli bersamaan. Mereka memiliki usia yang kurang lebih sama, dan telah digunakan dengan cara yang sama (disebut keausan). Banyak drive yang gagal karena masalah mekanis. Semakin tua usia drive, semakin aus bagian mekanisnya. Bagian mekanis yang sudah tua lebih mungkin gagal daripada yang lebih muda. Ini berarti bahwa kegagalan drive tidak lagi independen secara statistik. Dalam prakteknya, ada kemungkinan bahwa disk kedua juga akan gagal sebelum disk pertama dipulihkan. Ini berarti bahwa kehilangan data dapat terjadi pada tingkat yang signifikan, dalam praktiknya.
Atomisitas
Masalah lain yang juga terjadi pada sistem RAID adalah bahwa aplikasi mengharapkan apa yang disebut Atomicity: Entah semua data ditulis, atau tidak ada sama sekali. Menulis data dikenal sebagai transaksi.
Dalam array RAID, data baru biasanya ditulis di tempat di mana data lama berada. Hal ini dikenal sebagai update di tempat. Jim Gray, seorang peneliti database menulis sebuah makalah pada tahun 1981 di mana dia menggambarkan masalah ini.
Sangat sedikit sistem penyimpanan yang mengizinkan semantik penulisan atomik. Ketika sebuah objek ditulis ke disk, perangkat penyimpanan RAID biasanya akan menulis semua salinan objek secara paralel. Seringkali, hanya ada satu prosesor yang bertanggung jawab untuk menulis data. Dalam kasus seperti itu, penulisan data ke drive yang berbeda akan tumpang tindih. Ini dikenal sebagai penulisan yang tumpang tindih atau penulisan terhuyung-huyung. Oleh karena itu, kesalahan yang terjadi selama proses penulisan dapat meninggalkan salinan yang berlebihan dalam keadaan yang berbeda. Yang lebih buruk lagi, mungkin meninggalkan salinan dalam keadaan lama maupun baru. Logging bergantung pada data asli yang berada dalam keadaan lama atau baru. Hal ini memungkinkan backing out perubahan logis, tetapi hanya sedikit sistem penyimpanan yang menyediakan semantik penulisan atomik pada disk RAID.
Menggunakan cache tulis yang didukung baterai bisa mengatasi masalah ini, tetapi hanya dalam skenario kegagalan daya.
Dukungan transaksional tidak ada di semua pengontrol RAID perangkat keras. Oleh karena itu, banyak sistem operasi menyertakannya untuk melindungi terhadap kehilangan data selama penulisan yang terputus. Novell Netware, dimulai dengan versi 3.x, termasuk sistem pelacakan transaksi. Microsoft memperkenalkan pelacakan transaksi melalui fitur penjurnalan di NTFS. Sistem file NetApp WAFL menyelesaikannya dengan tidak pernah memperbarui data di tempat, seperti halnya ZFS.
Data yang tidak dapat dipulihkan
Beberapa sektor pada hard disk mungkin tidak dapat dibaca karena kesalahan. Beberapa implementasi RAID dapat menangani situasi ini dengan memindahkan data ke tempat lain dan menandai sektor pada hard disk sebagai bad. Hal ini terjadi sekitar 1 bit dalam 1015 pada disk drive kelas enterprise, dan 1 bit dalam 1014 pada disk drive biasa. Kapasitas disk terus meningkat. Hal ini dapat berarti bahwa kadang-kadang, RAID tidak dapat dibangun kembali, karena kesalahan seperti itu ditemukan ketika array dibangun kembali setelah kegagalan disk. Teknologi tertentu seperti RAID 6 mencoba untuk mengatasi masalah ini, tetapi mereka menderita write penalty yang sangat tinggi, dengan kata lain menulis data menjadi sangat lambat.
Keandalan cache tulis
Sistem disk dapat mengetahui operasi tulis segera setelah data berada dalam cache. Tidak perlu menunggu sampai data telah ditulis secara fisik. Namun demikian, pemadaman listrik apa pun bisa berarti kehilangan data yang signifikan dari data apa pun yang antri dalam cache tersebut.
Dengan RAID perangkat keras, baterai dapat digunakan untuk melindungi cache ini. Ini sering memecahkan masalah. Ketika daya gagal, pengontrol dapat menyelesaikan penulisan cache ketika daya kembali. Solusi ini masih bisa gagal: baterai mungkin telah aus, daya mungkin telah mati terlalu lama, disk bisa dipindahkan ke pengontrol lain, pengontrol itu sendiri bisa gagal. Sistem tertentu dapat melakukan pemeriksaan baterai secara periodik, tetapi ini menggunakan baterai itu sendiri, dan membiarkannya dalam keadaan tidak terisi penuh.
Kompatibilitas peralatan
Format disk pada pengontrol RAID yang berbeda belum tentu kompatibel. Oleh karena itu, mungkin tidak mungkin untuk membaca array RAID pada perangkat keras yang berbeda. Akibatnya, kegagalan perangkat keras non-disk mungkin memerlukan penggunaan perangkat keras yang identik, atau cadangan, untuk memulihkan data.
Apa yang bisa dan tidak bisa dilakukan RAID
Panduan ini diambil dari sebuah thread di forum yang berhubungan dengan RAID. Hal ini dilakukan untuk membantu menunjukkan keuntungan dan kerugian dari memilih RAID. Hal ini diarahkan pada orang-orang yang ingin memilih RAID baik untuk peningkatan kinerja atau redundansi. Ini berisi tautan ke thread lain di forumnya yang berisi ulasan anekdotal yang dibuat pengguna tentang pengalaman RAID mereka.
Apa yang bisa dilakukan RAID
- RAID dapat melindungi waktu kerja. RAID level 1, 0+1/10, 5 dan 6 (dan variannya seperti 50 dan 51) dapat mengatasi kegagalan hard disk mekanis. Bahkan setelah hard disk gagal, data pada array masih dapat digunakan. Alih-alih pemulihan yang memakan waktu dari tape, DVD atau media cadangan lambat lainnya, RAID memungkinkan data untuk dipulihkan ke disk pengganti dari anggota array lainnya. Selama proses restorasi ini, tersedia bagi pengguna dalam keadaan terdegradasi. Ini sangat penting bagi perusahaan, karena downtime dengan cepat menyebabkan hilangnya daya penghasilan. Bagi pengguna rumahan, ini dapat melindungi uptime array penyimpanan media besar, yang akan memerlukan restorasi yang memakan waktu dari lusinan DVD atau beberapa kaset jika terjadi kegagalan disk yang tidak dilindungi oleh redundansi.
- RAID dapat meningkatkan kinerja dalam aplikasi tertentu. RAID level 0, 5 dan 6 semuanya menggunakan striping. Hal ini memungkinkan beberapa spindel untuk meningkatkan kecepatan transfer untuk transfer linear. Aplikasi tipe workstation sering bekerja dengan file besar. Mereka sangat diuntungkan dari striping disk. Contoh untuk aplikasi semacam itu adalah yang menggunakan file video atau audio. Throughput ini juga berguna dalam backup disk-ke-disk. RAID 1 serta level RAID berbasis striping lainnya dapat meningkatkan kinerja untuk pola akses dengan banyak akses acak simultan, seperti yang digunakan oleh database multi-pengguna.
Apa yang tidak bisa dilakukan RAID
- RAID tidak dapat melindungi data pada array. Array RAID memiliki satu sistem file. Ini menciptakan satu titik kegagalan. Ada banyak hal yang dapat terjadi pada sistem file ini selain kegagalan disk fisik. RAID tidak dapat bertahan terhadap sumber-sumber kehilangan data ini. RAID tidak akan menghentikan virus dari menghancurkan data. RAID tidak akan mencegah korupsi. RAID tidak akan menyimpan data ketika pengguna memodifikasinya atau menghapusnya secara tidak sengaja. RAID tidak melindungi data dari kegagalan perangkat keras dari komponen apa pun selain disk fisik. RAID tidak melindungi data dari bencana alam atau bencana buatan manusia seperti kebakaran dan banjir. Untuk melindungi data, data harus dicadangkan ke media yang dapat dilepas, seperti DVD, tape, atau hard disk eksternal. Backup harus disimpan di tempat yang berbeda. RAID saja tidak akan mencegah bencana, ketika (bukan jika) bencana itu terjadi, berubah menjadi kehilangan data. Bencana tidak dapat dicegah, tetapi backup memungkinkan kehilangan data dapat dicegah.
- RAID tidak dapat menyederhanakan pemulihan bencana. Saat menjalankan disk tunggal, disk dapat digunakan oleh sebagian besar sistem operasi karena dilengkapi dengan driver perangkat umum. Namun, sebagian besar pengontrol RAID membutuhkan driver khusus. Alat pemulihan yang bekerja dengan disk tunggal pada pengontrol generik akan memerlukan driver khusus untuk mengakses data pada array RAID. Jika alat pemulihan ini dikodekan dengan buruk dan tidak memungkinkan penyediaan driver tambahan, maka array RAID mungkin tidak dapat diakses oleh alat pemulihan itu.
- RAID tidak dapat memberikan peningkatan kinerja di semua aplikasi. Pernyataan ini terutama berlaku pada pengguna aplikasi desktop dan gamer. Untuk sebagian besar aplikasi desktop dan game, strategi buffer dan kinerja pencarian disk lebih penting daripada throughput mentah. Meningkatkan kecepatan transfer mentah yang berkelanjutan menunjukkan sedikit keuntungan bagi pengguna tersebut, karena sebagian besar file yang mereka akses biasanya sangat kecil. Disk striping menggunakan RAID 0 meningkatkan performa transfer linear, bukan performa buffer dan seek. Akibatnya, striping disk menggunakan RAID 0 menunjukkan sedikit atau tidak ada peningkatan kinerja di sebagian besar aplikasi desktop dan game, meskipun ada pengecualian. Untuk pengguna desktop dan gamer dengan performa tinggi sebagai tujuan, lebih baik membeli disk tunggal yang lebih cepat, lebih besar, dan lebih mahal daripada menjalankan dua drive yang lebih lambat/kecil dalam RAID 0. Bahkan menjalankan drive terbaru, terhebat, dan terbesar dalam RAID-0 tidak mungkin meningkatkan kinerja lebih dari 10%, dan kinerja dapat menurun dalam beberapa pola akses, terutama game.
- Sulit untuk memindahkan RAID ke sistem baru. Dengan disk tunggal, relatif mudah untuk memindahkan disk ke sistem baru. Disk ini dapat dengan mudah dihubungkan ke sistem baru, jika tersedia antarmuka yang sama. Namun, hal ini tidak semudah itu dengan array RAID. Ada jenis Metadata tertentu yang mengatakan bagaimana RAID diatur. RAID BIOS harus dapat membaca metadata ini sehingga dapat berhasil membangun array dan membuatnya dapat diakses oleh sistem operasi. Karena pembuat pengontrol RAID menggunakan format yang berbeda untuk metadata mereka (bahkan pengontrol dari keluarga yang berbeda dari produsen yang sama dapat menggunakan format metadata yang tidak kompatibel) hampir tidak mungkin untuk memindahkan array RAID ke pengontrol yang berbeda. Ketika memindahkan array RAID ke sistem baru, rencana harus dibuat untuk memindahkan controller juga. Dengan popularitas pengendali RAID terintegrasi motherboard, hal ini sangat sulit. Umumnya, adalah mungkin untuk memindahkan anggota array RAID dan kontroler bersama-sama. Software RAID di Linux dan Produk Windows Server juga dapat mengatasi keterbatasan ini, tetapi software RAID memiliki keterbatasan lainnya (kebanyakan terkait kinerja).
Contoh
Level RAID yang paling sering digunakan adalah RAID 0, RAID 1, dan RAID 5. Misalkan ada pengaturan 3 disk, dengan 3 disk identik masing-masing 1 TB, dan kemungkinan kegagalan drive untuk rentang waktu tertentu adalah 1%.
| Tingkat RAID | Kapasitas yang dapat digunakan | Kemungkinan kegagalan diberikan dalam persen | Kemungkinan kegagalan 1 dalam ... kasus gagal |
| 0 | 3 TB | 2,9701% | 34 |
| 1 | 1 TB | 0,0001% | 1 juta |
| 5 | 2 TB | 0,0298% | 3356 |
Penulis
AlegsaOnline.com RAID Leandro Alegsa
URL: https://id.alegsaonline.com/art/80859
Sumber
- www-2.cs.cmu.edu : ""A Case for Redundant Arrays of Inexpensive Disks" - Patterson, Gibson, Katz"
- thomason.org : "RAID: High-Performance, Reliable Secondary Storage"
- baarf.com : "BAARF - Battle Against Any Raid Five"
- media.netapp.com : "RAID-DP™: Network Appliance™ implementation of RAID Double Parity for data protection, a high speed implementation of RAID 6"
- nasi.com : "IBM X-Architecture Technology 2001:A design blueprint for Intel processor-based servers"
- pcguide.com : "RAID Level 7"
- cgi.cse.unsw.edu.au : "Linux RAID 10 driver"
- linux-raid.osdl.org : "Main Page - Linux-raid"
- blogs.sun.com : "RAID-Z : Jeff Bonwick's Blog"
- blogs.sun.com : "Adam Leventhal's Weblog"
- research.microsoft.com : "Empirical Measurements of Disk Failure Rates and Error Rates"
- usenix.org : "Disk Failures in the Real World: What Does an MTTF of 1,000,000 Hours Mean to You?"
- research.microsoft.com : "The Transaction Concept: Virtues and Limitations (Invited Paper)¦format=pdf"
- informatik.uni-trier.de : "VLDB 1981"
- arxiv.org : "Empirical Measurements of Disk Failure Rates and Error Rates"