Hukum Zipf
Hukum Zipf adalah hukum empiris, yang diformulasikan menggunakan statistik matematika, dinamai sesuai dengan nama ahli bahasa George Kingsley Zipf, yang pertama kali mengusulkannya. Hukum Zipf menyatakan bahwa jika diberikan sampel besar kata ya…
Hukum Zipf adalah hukum empiris, yang diformulasikan menggunakan statistik matematika, dinamai sesuai dengan nama ahli bahasa George Kingsley Zipf, yang pertama kali mengusulkannya.
Hukum Zipf menyatakan bahwa jika diberikan sampel besar kata yang digunakan, frekuensi kata apa pun berbanding terbalik dengan peringkatnya dalam tabel frekuensi. Jadi kata nomor n memiliki frekuensi yang sebanding dengan 1/n.
Dengan demikian, kata yang paling sering muncul akan muncul sekitar dua kali lebih sering daripada kata kedua yang paling sering muncul, tiga kali lebih sering daripada kata ketiga yang paling sering muncul, dll. Misalnya, dalam satu sampel kata dalam bahasa Inggris, kata yang paling sering muncul, "the", menyumbang hampir 7% dari semua kata (69.971 dari sedikit lebih dari 1 juta). Sesuai dengan Hukum Zipf, kata "of" di tempat kedua menyumbang sedikit lebih dari 3,5% kata (36.411 kemunculan), diikuti oleh "and" (28.852). Hanya sekitar 135 kata yang diperlukan untuk menjelaskan setengah dari sampel kata dalam sampel yang besar.
Hubungan yang sama terjadi dalam banyak peringkat lainnya, yang tidak terkait dengan bahasa, seperti peringkat populasi kota di berbagai negara, ukuran perusahaan, peringkat pendapatan, dll. Munculnya distribusi dalam peringkat kota berdasarkan populasi pertama kali diperhatikan oleh Felix Auerbach pada tahun 1913.
Tidak diketahui mengapa hukum Zipf berlaku untuk sebagian besar bahasa.
Galeri gambar
3 Gambar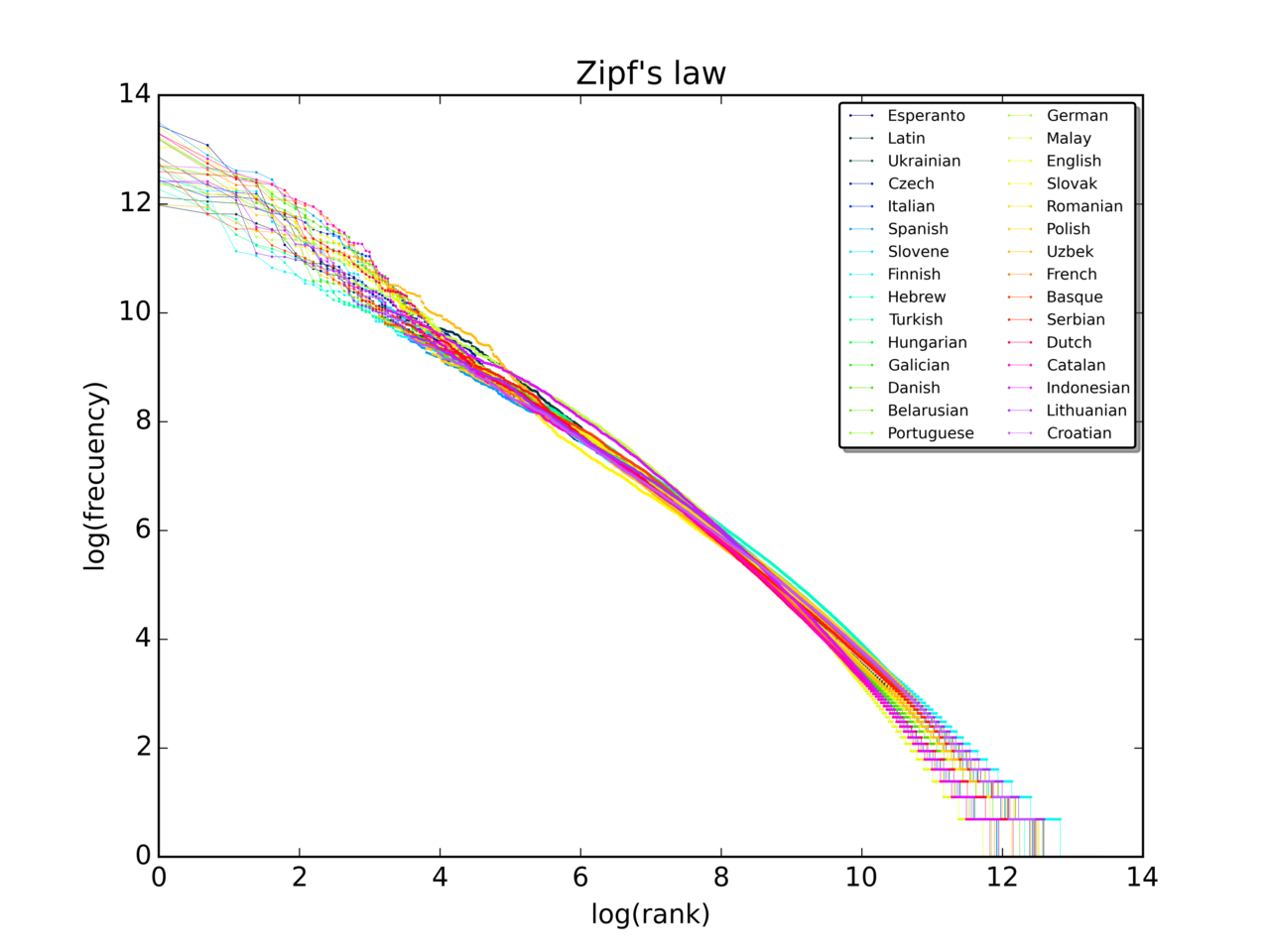


Pertanyaan dan jawaban
T: Apa yang dimaksud dengan hukum Zipf?
J: Hukum Zipf adalah hukum empiris yang menyatakan bahwa frekuensi sebuah kata dalam sampel yang besar berbanding terbalik dengan peringkatnya dalam tabel frekuensi.
T: Siapa yang mengusulkan hukum Zipf?
J: Hukum Zipf pertama kali diusulkan oleh George Kingsley Zipf, seorang ahli bahasa.
T: Bagaimana hukum Zipf menjelaskan frekuensi kata dalam sampel kata-kata bahasa Inggris?
J: Menurut hukum Zipf, kata yang paling sering muncul dalam sampel kata bahasa Inggris muncul sekitar dua kali lebih sering daripada kata yang paling sering muncul kedua, tiga kali lebih sering daripada kata yang paling sering muncul ketiga, dan seterusnya. Tren ini terus berlanjut seiring dengan menurunnya peringkat kata tersebut.
T: Berapa persen dari semua kata yang paling sering muncul dalam satu sampel kata bahasa Inggris?
J: Dalam satu sampel kata bahasa Inggris, kata yang paling sering muncul ("the") menyumbang hampir 7% dari semua kata.
T: Apa hubungan antara jumlah kata yang dibutuhkan untuk mencakup setengah dari sampel dan frekuensi kata-kata tersebut?
J: Menurut hukum Zipf, hanya sekitar 135 kata yang dibutuhkan untuk menjelaskan setengah sampel kata dalam sampel besar.
T: Peringkat apa lagi yang menunjukkan hukum Zipf?
J: Hubungan yang sama yang digambarkan oleh hukum Zipf dalam frekuensi kata terjadi pada peringkat lain yang tidak terkait dengan bahasa, seperti peringkat populasi kota di berbagai negara, ukuran perusahaan, dan peringkat pendapatan.
T: Siapa yang memperhatikan kemunculan distribusi dalam peringkat kota berdasarkan populasi?
J: Kemunculan distribusi peringkat kota berdasarkan jumlah penduduk pertama kali diketahui oleh Felix Auerbach pada tahun 1913.
Artikel terkait
Penulis
AlegsaOnline.com Hukum Zipf Leandro Alegsa
URL: https://id.alegsaonline.com/art/110649
Sumber
- books.google.com : P. 139